Collection and Masking the Data¶
Our first and foremost goal is to collect the data’s that is needed for the next step.
Data Collection¶
We started our path with collecting the data’s from different sources..
Our Mentors has reduced the work for us by collecting both
`Library-data`and`Exam-cell data `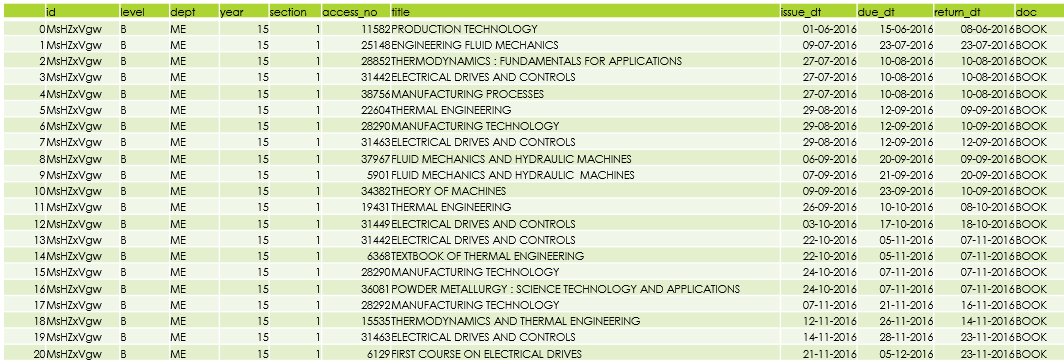
Sample Image of Library Transaction data…
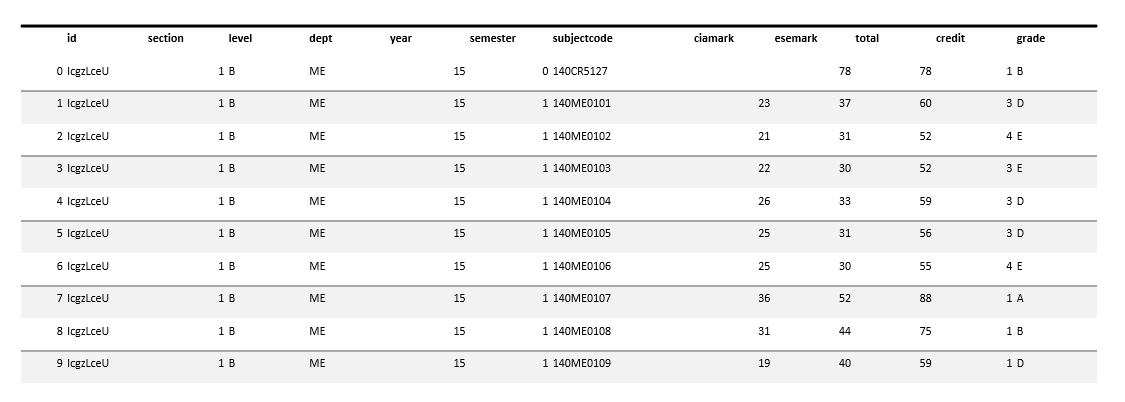
Sample Image of Exam-cell data…
Data Masking¶
After data collection process, we can’t use the sensitive information of student..
So our plan is to implement a function which can take the students
**Roll.No**and mask them with a unique id..We got both the data without
** Roll.No **column, where the sensitive information will not be revealed..Importing required libraries …
import numpy as np import pandas as pd from django.utils.crypto import get_random_stringImporting the data …
st_list = pd.read_excel('useridsalone-2.xlsx',sheet_name=2) st_book_trans_lib = pd.read_excel('useridsalone-2.xlsx',sheet_name=1) st_entry_lib = pd.read_excel('useridsalone-2.xlsx',sheet_name=0)A code block of our function is given below:
def idmap(st_data,records): no_of_students = len(st_data['roll_no']) n = pd.Series(np.arange(0,no_of_students,step=1)) n = n.map(str) st_data['id']=n.apply(lambda x: get_random_string(8)) records.columns = ['roll_no'] records['batch_no'] = records.roll_no.str[0:2] records['prog'] = records.roll_no.str[2] records['prog'] = list(map(lambda x : x.upper(),records.prog)) records['dept'] = records.roll_no.str[3:5] records['dept'] = list(map(lambda x : x.upper(),records.dept)) records['roll_no_num'] = records.roll_no.str[5:] records['roll_no']=records['batch_no'].map(str)+records['prog'].map(str)+records['dept'].map(str)+records['roll_no_num'].map(str) #filtering filt = (records['dept'] == 'ME') & (records['prog'] == 'B') records = records.loc[filt] df_name = pd.merge(records,st_data,how='right',on='roll_no') df_name.drop(columns=['roll_no','roll_no_num'],inplace=True) df_name.to_csv('.csv') # df.head() return df_nameIn the above function we have accomplished masking the
`roll_no`with unique`id's`and further some`string operations`..